Parsen von KDP Transaction Reports
Als Autor von mehreren Büchern im Eigenverlag bekomme ich regelmäßig Aufstellungen über die Anzahl der verkauften Bücher und deren Erlöse. Diese Aufstellungen kommen in den unterschiedlichsten Formaten, so dass ich sie für die Weiterverarbeitung erst einmal konvertieren muss.
Dabei stellte sich heraus, dass die Aufstellungen von Kindle Desktop Publishing (KDP) ein interessantes Format haben Diese kommen als Excel-Dateien, was zunächst den Gedanken an eine leichte Weiterverarbeitung aufkommen lässt. Allerdings sind es keine simplen Tabellen, sondern strukturierte Texte, die auf die verschiedenen Zellen verteilt sind.
Zu allem Überfluss hat sich das Format der Tabellen während der Zeit, in der ich die Reports bekomme, bereits mindestens zweimal geändert. Die Reports sehen ungefähr so aus:
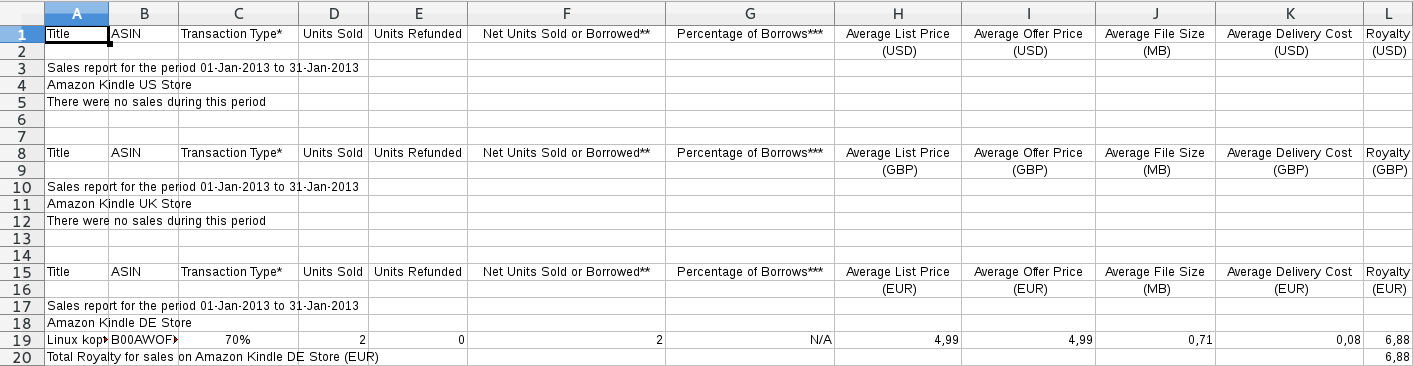
oder so:
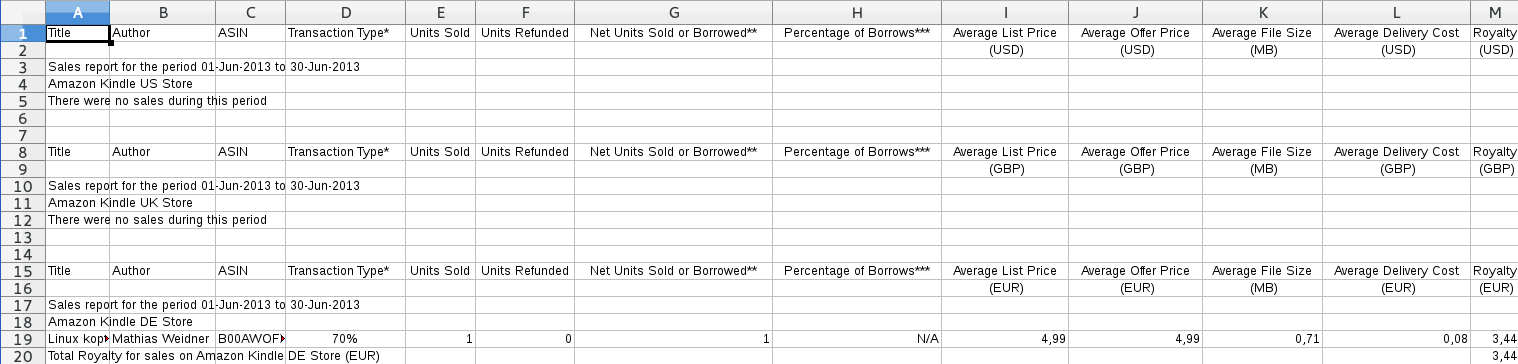
oder so:
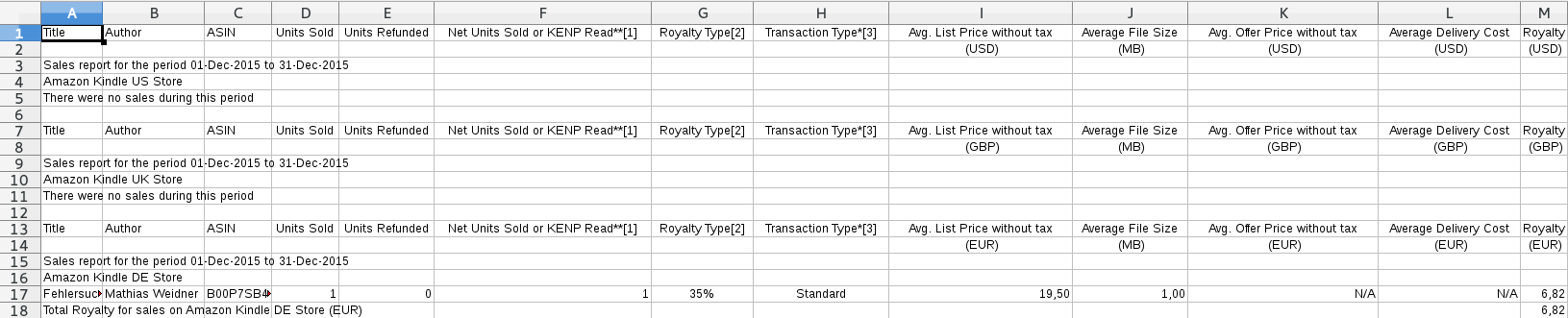
Davon interessieren mich vor allem die folgenden Informationen:
- Die Währung in Spalte L oder M der nächsten Zeile, nach der Zeile, die mit "Title" in der ersten Spalte beginnt.
- Das Datum aus der Verkaufsperiode in der ersten Spalte der zweiten Zeile nach der, die mit "Title" beginnt.
- Der Store, in dem das Buch verkauft wurde, in der ersten Spalte der dritten Zeile nach der, die mit "Title" in der ersten Spalte beginnt.
- Der Titel des Buches in der ersten Spalte, dieser startet einen Verkaufsdatensatz.
- Die ASIN in der zweiten Spalte als eindeutige ID des Buches.
- Die Anzahl der verkauften Bücher (Units sold) in Spalte D oder E.
- Das Honorar (Royalty) in Spalte L oder M.
Wie komme ich nun an diese Informationen? Das Mittel der Wahl ist für mich natürlich Perl, mit dem Modul SpreadSheet::ParseExcel habe ich hier genau das richtige Werkzeug, um an den Inhalt der Reports zu kommen.
Meine erste, naive Herangehensweise war, über die Zeilen und Spalten zu iterieren, diese dabei abzuzählen und aus bestimmten, vorab festgelegten Zellen die benötigten Informationen zu entnehmen. Das hatte ich schnell programmiert, die interessanten Zellen vorher mit oocalc ermittelt.
Damit konnte ich die ersten Reports einlesen, irgendwann funktionierte es jedoch nicht mehr. Das war der Augenblick, als mir zum ersten Mal auffiel, das sich das Format geändert hat.
Egal dachte ich, programmierte Ausnahmen in das Programm und konnte wieder alle Reports einlesen. Bis zur nächsten Änderung.
Das brachte mich dazu, nachzudenken. Die bisherige Lösung war fragil, fehlerträchtig und wird mit jeder Formatänderung schlimmer, da immer mehr Ausnahmen programmiert werden müssen.
Bei genauer Betrachtung der Unterschiede in den Format-Versionen fiel mir auf, dass diese nicht bei den Informationen lagen, die ich haben wollte, sondern lediglich deren Position verschoben wurde. Also wollte ich etwas haben, dass die Informationen unabhängig von ihrer Position fand.
Ich erinnerte mich an ein Konzept, dass ich bereits vor vielen Jahren kennengelernt hatte, früher auch häufig selbst einsetzte, aber in letzter Zeit wenig gebraucht habe: ein Zustandsautomat.
Sehr vereinfacht ausgedrückt, ist ein Zustandsautomat ein Programm, das sich bei den gleichen Eingangsdaten je nach innerem Zustand unterschiedlich verhält. Das schöne daran: man kann den Zustandsautomat als Graphen darstellen und damit komplexe Sachverhalte auch nichttechnischem Publikum (hoffentlich) erklären.
Denn egal, wie komplex das Problem ist, in einem bestimmten Zustand reagiert das Programm nur auf relativ wenige Eingangsdaten mit simplen Aktionen. Und in welchem Zustand es sich befindet kann man anhand des Graphen sehr leicht nachvollziehen.
Ein Zustandsautomat sollte es also sein. Für die KDP-Reports sieht dieser recht simpel aus:
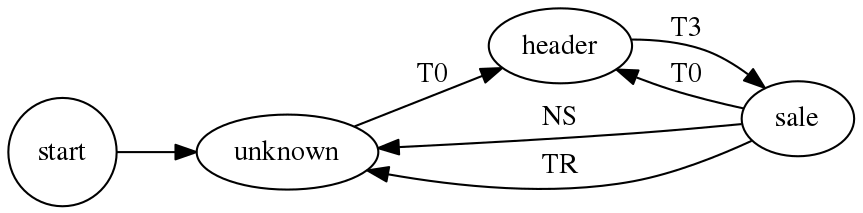
Nach dem Start ist dem Automat zunächst egal, wo genau er in der Tabelle ist, er geht in den Zustand unknown. Er liest Zellen zeilen- und spaltenweise ein, bis er zu einer kommt, die sich in Spalte A befindet und deren Inhalt das Wort "Title" ist (T0). Damit weiß er, dass er in einer Kopfzeile ist, merkt sich die Zeilennummer und geht über in den Zustand header.
Solange er in der selben Zeile ist, schaut er sich die Zelleninhalte an, die Überschriften für die folgenden Verkaufsdaten darstellen. Dabei merkt er sich die Spaltennummern der interessierenden Daten. In der nächsten Zeile findet er ergänzende Informationen, wie zum Beispiel die Währung.
Nach der dritten Zeile (T3) wechselt er in den Zustand sale und sammelt die Verkaufsdaten ein. Jeweils in einer Zeile sammelt er die Daten aus den Spalten, die er im Zustand header ermittelt hat. Beginnt eine neue Zeile, speichert er die gesammelten Daten als Record ab. Beginnt eine Zelle in Spalte A mit "There were no sales" (NS) oder "Total Royalty" (TR), ist er am Ende der Verkaufsdaten und geht wieder in den Zustand unknown
Zur Sicherheit, falls er die Ereignisse NS oder TR verpasst, wechselt er sofort in den Zustand header, wenn er das Wort "Title" in einer Zelle der ersten Spalte entdeckt. Das hat den Vorteil, dass der Zustandsautomat stabiler gegenüber den Schlußzeilen (NS, TR) bei den Verkäufen wird. Dafür läuft er allerdings auf einen Fehler, wenn ich ein Buch mit dem Titel "Title" bei KDP veröffentliche. Hier kann man noch ein paar Sicherheitstests einbauen.
Dieses Verfahren ist stabil gegenüber Änderungen in den Spalten, ich kann damit alle drei mir momentan vorliegenden Formate einlesen.
Implementierung
Ich habe den Zustandsautomat in einem Perl-Objekt implementiert.
sub new {
my ($self) = @_;
my $type = ref($self) || $self;
$self = bless {
sales => [],
state => 'unknown',
hsrow => 0,
tbkrow => 0,
}, $type;
return $self;
}
Dieses Objekt speichert die Verkaufsdaten (sales), den aktuellen Zustand (state), die Zeilennummer, in der die Kopfdaten begannen (hsrow) und die Zeilennummer für das aktuelle Buch.
Der Automat selbst ist in der Methode _cell_handler() implementiert.
sub _cell_handler {
my ($self,$workbook,$sheetindex,$row,$col,$cell) = @_;
...
my $states = {
'unknown' => sub {
my ($row,$col,$cell) = @_;
if (0 == $col && 'Title' eq $cell->value()) {
...
return 'header';
}
return 'unknown';
},
'header' => sub {
my ($row,$col,$cell) = @_;
...
return 'header';
},
'sale' => sub {
my ($row,$col,$cell) = @_;
...
return 'sale';
},
};
my $state = $self->{state};
$self->{state} = $states->{$state}->($row,$col,$cell);
}
In dieser Methode gibt es eine Hash, deren Schlüssel die Zustände des Automaten (unknown, header, sale) sind, während die Werte anonyme Funktionen sind, die die aktuelle Zeile, die Spalte und den Inhalt der Zelle verarbeiten.
Der Automat als solcher wird in den letzten beiden Zeilen ausgeführt: er
lädt den aktuellen Zustand und führt die zugehörige Funktion aus der
Hash $states aus.
Diese Funktion liefert als Rückgabewert den nächsten Zustand.
Als Voreinstellung liefert jede Funktion den Zustand zurück, zu dem sie selbst gehört. Nur wenn ein bestimmtes Ereignis auftritt, wie zum Beispiel für den Zustand unknown ausgeführt, liefert die Funktion einen anderen Folgezustand. Alle weiteren Aktionen, wie das Zwischenspeichern der relevanten Spaltennummern oder das Füllen der Verkaufsliste finden ebenfalls in den Zustandsfunktionen statt.
Schmankerl
Liest man die Handbuchseite von SpreadSheet::ParseExcel bis zum Ende, so findet man dort eine Möglichkeit, Speicherplatz beim Einlesen der Excel-Tabelle zu sparen. Die Details lasse ich hier weg, die stehen in der Handbuchseite.
Um Speicherplatz zu sparen gebe ich dem ParseExcel-Objekt beim Erzeugen
mit new() eine Callback-Funktion mit, die alle Daten der aktuellen
Zelle als Argumente beim Aufruf bekommt.
ParseExcel selbst speichert in diesem Fall keine Zellendaten.
Wenn ich mit einer Callback-Funktion arbeite, muss ich mich nicht um das Iterieren über die Zeilen und Spalten kümmern, das macht ParseExcel. Mein Code wird in dieser Hinsicht also übersichtlicher. Da ich sowieso einen Zustandsautomaten implementieren will, der auf bestimmte Zellen der Tabelle reagiert, kommt mir das sogar entgegen.
Da ist nur ein winziges Problem: diese Callback-Funktion wird von ParseExcel aufgerufen und bekommt als Parameter Arbeitsbuch, Index des aktuellen Blattes, Zeile, Spalte und Zelle, aber nicht den aktuellen Zustand, den ich für den Zustandsautomaten benötige.
Doch Perl wäre nicht Perl, wenn es nicht auch dafür eine elegante Lösung
hätte.
ParseExcel::new() will einen Verweis auf eine Funktion und keinen
Funktionsnamen.
Ich kann hier eine anonyme Funktion, ein Closure, übergeben, die
ihrerseits den Zustand zwischen mehreren Aufrufen bewahrt und
somit meinen Zustandsautomaten implementiert.
sub read {
my ($self,$fname) = @_;
my $cell_handler = sub {
$self->_cell_handler(@_);
};
my $parser = Spreadsheet::ParseExcel->new(
CellHandler => $cell_handler,
NotSetCell => 1,
);
$parser->parse($fname);
return $self->{sales};
}
Damit wird die Methode zum lesen der KDP-Reports sehr einfach.
Ich erzeuge eine Closure ($cell_handler), die alle übergebenen
Parameter an die Methode _cell_handler() durchreicht.
Diese Closure übergebe ich als Callback-Funktion an
Spreadsheet::ParseExcel->new() und rufe dessen Funktion parse() auf.
Am Ende finde ich die Verkaufsdaten in der Variable sales des
aktuellen Objekts und kann sie zurückgeben.