Verlorene MAC-Adresse
Es war ein seltsames Problem und restlos geklärt habe ich es auch nicht. Sobald ich das Wesentliche verstanden hatte und es abstellen konnte, drängten sich andere Dinge in den Vordergrund und es blieb keine Zeit, die letzte Ursache zu ergründen.
Was war passiert?
Ein Kunde meldete sich, weil er Probleme hatte, von verschiedenen Standorten aus einen Server im Rechenzentrum zu erreichen. Es war nicht so, dass gar nichts ging. Vielmehr brach die Verbindung ständig kurzzeitig ab und funktionierte wieder, brach wieder ab und so weiter.
Ein Kollege hatte sich schon an dem Problem versucht und bei einem Dauer-Ping festgestellt, dass etwa 16 Prozent Paketverluste auftraten. Jeweils nach 50 Sekunden setzten die Ping-Antworten für etwa 10 Sekunden aus und funktionierten dann wieder für 50 Sekunden.
Weil innerhalb des Rechenzentrums keine Probleme mit dem Server auftraten, sondern nur an den Standorten, die alle über den gleichen Provider angebunden waren, sahen wir das Problem schon beim Provider. Dieser jedoch fand nichts in seinen Netzen.
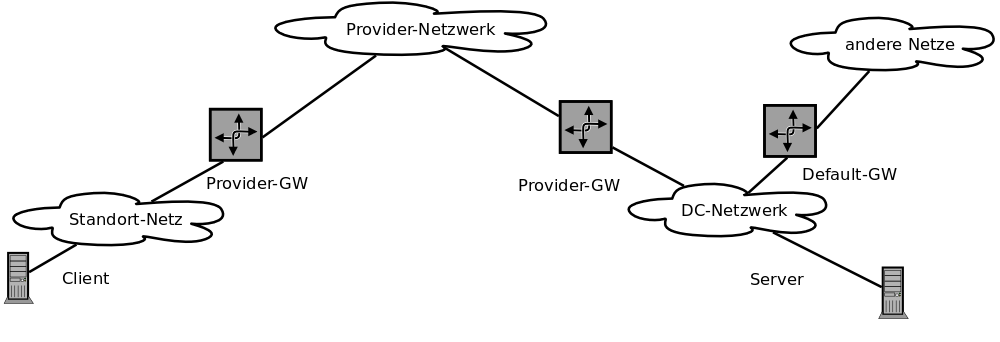
Zur Orientierung habe ich die Topologie aufgezeichnet. Das Bild lässt eine Ursache des Problems schon erahnen: hier befinden sich mehreres Gateways im selben Netz wie die Endgeräte.
Eine Kontrolle der Routingtabelle am Server zeigte, dass die Datagramme im Rechenzentrum asymmetrisch liefen. Nämlich vom Server zum Default-Gateway und von dort über das Provider-Gateway zum Standort. Die Antworten gingen direkt über das Provider-Gateway zum Server.
Das Konstrukt "riecht" schon verdächtig, aber das Default-Gateway hatte keine Firewall-Regeln und ein Paketmitschnitt dort zeigte, dass es alle PING-Datagramme zum Provider-Gateway weiter leitete. An dieser Stelle traten keine Verluste auf und auch das Verhalten konnte damit nicht erklärt werden.
Das verstärkte bei mir den Verdacht, dass es sich doch um ein Problem beim Provider handeln könnte.
Aber der Server und die beiden Gateways waren nicht die einzigen Systeme, die im Rechenzentrum beteiligt waren. Also untersuchte ich das Problem auf Layer 2, um gegenüber dem Provider handfeste Argumente zu haben, dass er noch einmal gezielt nachsehen müsse.
Der Server und das Default-Gateway sind virtuelle Maschinen, die auf verschiedenen Hosts laufen. Zwischen den Hosts werden die Datagramme via VXLAN transportiert, von und zum Provider-Gateway in einem VLAN über mehrere Switches.
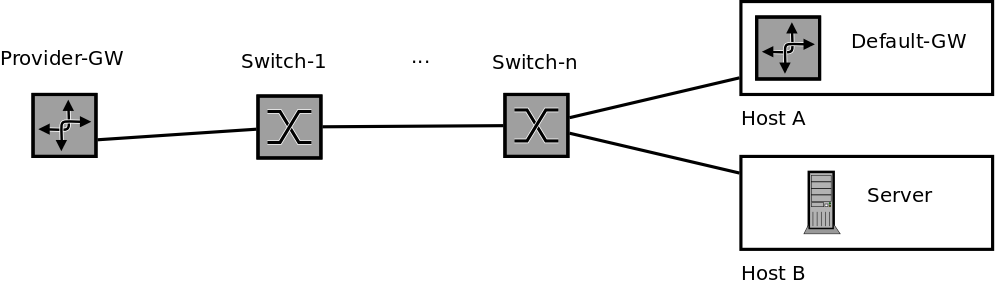
Die konkrete Verbindung der Switches untereinander sowie der Hosts und des Provider-Gateways zu den Switches ist für das grundlegende Verständnis nicht nötig.
Datagramme zwischen Default-Gateway und Server werden in VXLAN gekapselt zwischen den Hosts ausgetauscht. Die Switches sehen hierbei die MAC-Adressen der virtuellen Maschinen nicht.
Datagramme vom Default-Gateway liefert Host A an das VLAN bei seinem Switch und von dort geht es über die anderen Switches zum Provider-Gateway.
Wenn die Antwort vom Standort kommt, erfragt das Provider-Gateway die MAC-Adresse des Servers via ARP. Die Anfrage wird im VLAN geflutet und gelangt via Host B zum Server. Dieser teilt seine MAC-Adresse via ARP mit und damit kennt sie das Provider-Gateway. Gleichzeitig lernen alle beteiligten Switches, an welchen Ports diese MAC-Adresse zu finden ist.
Da der Server die Datagramme nicht direkt zum Provider-Gateway sendet, sondern an das Default-Gateway, taucht die MAC-Adresse des Servers bei den Switches in keinem weiteren Datagramm als Absender auf. Nach etwa 50 Sekunden "vergessen" die Switches die dynamisch gelernte MAC-Adresse und wissen nicht mehr, an welchen Port sie die Datagramme zum Server senden müssen. Das Provider-Gateway hingegen hat die MAC-Adresse noch in seinem ARP-Cache und sendet weiter Datagramme an die MAC-Adresse des Servers.
Nach 60 Sekunden, also etwa 10 Sekunden nachdem die Switches den Port vergessen haben, verschwindet die MAC-Adresse aus dem ARP-Cache des Provider-Gateways. Dieses stellt eine neue ARP-Anfrage und mit der Antwort darauf lernen die Switches wieder den Port, zu dem sie die Datagramme weiterleiten müssen. Nun kommen die Ping-Antworten vom Standort auch wieder beim Server an.
Um diese Hypothese zu untermauern, starteten wir parallel zu dem Ping zum Standort einen zweiten Dauer-Ping zum Provider-Gateway auf dem Server. Damit gab es Datagramme direkt vom Server zum Provider-Gateway, die Switches behielten die MAC-Adresse in ihrer Tabelle und es gab keine Ausfälle beim Ping zum Standort.
Natürlich müssten die Switches die Datagramme, deren Ziel-MAC-Adresse sie nicht kannten, an allen Ports des betreffenden VLANs fluten. Das habe ich nicht geprüft und daher bleibt offen, ob nicht alle Switches die Datagramme geflutet haben oder die gefluteten Datagramme beim Übergang vom Switch zum Host verloren gingen.
Dass die Switches die MAC-Adresse vergessen, fiel mir nur darum auf, weil ich den Weg der Datagramme von einem Switch zum anderen untersuchte und auf einmal die Adresse nicht mehr in der MAC-Tabelle fand und zwar genau dann, wenn gerade keine Ping-Antworten beim Server ankamen. Wann immer möglich versuche ich, solche Konstrukte zu vermeiden.
Was bleibt, ist einmal mehr die Erkenntnis, dass mehrere Gateways in einem Netz mit Endpunkten keine gute Idee sind. Genauso, wie asymmetrischer Datenverkehr.
Nachtrag
In [1] wird das Problem mit Unicast-Flooding für Switches bei asymmetrischem Routing ausführlich beschrieben. Dort wird als Lösung vorgeschlagen, den ARP-Timeout am Router und die Table-Aging-Time an den Switches anzugleichen, so dass der Router einen neuen ARP-Request sendet, bevor die Switches die MAC-Adresse "vergessen".
Diese Lösung wäre für uns nur durch Anpassung der Switch-Timer möglich, weil der Provider Router nicht von uns verwaltet wird.
Außerdem erfordert sie einen expliziten Eingriff bei allen Switches zwischen Provider-Router und Server-VM, der dokumentiert und in der Dokumentation begründet werden muss, damit später immer noch jemand weiß, warum diese Timer auf andere Werte gesetzt wurden.
Aus diesem Grund haben wir uns für eine statische Route auf der Server-VM als Zwischenlösung und für das Eliminieren des asymmetrischen Routings als langfristige Lösung entschieden.
[1] Cisco 23563: Unicast Flooding in Switched Campus Networks
Posted 2022-03-19